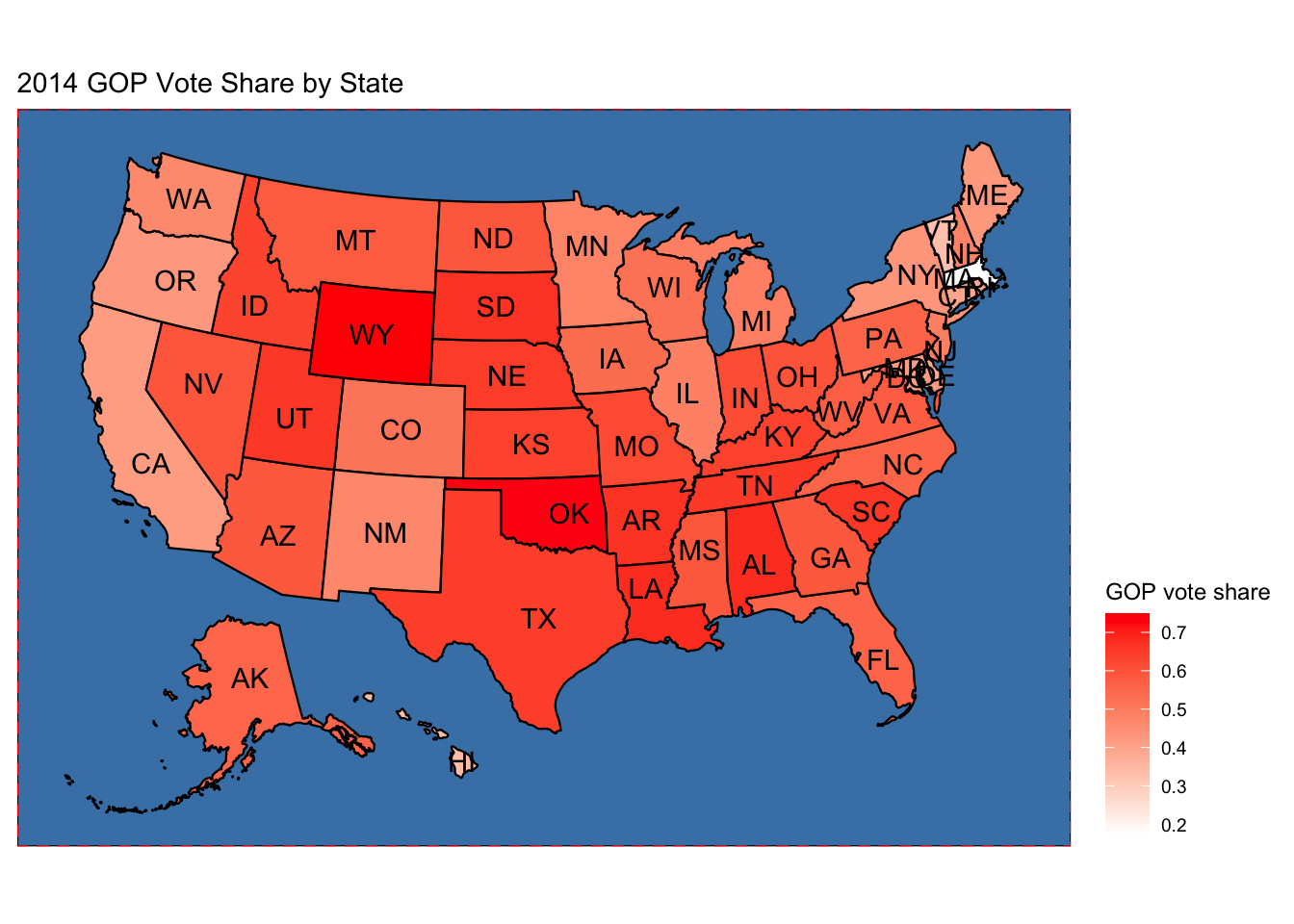
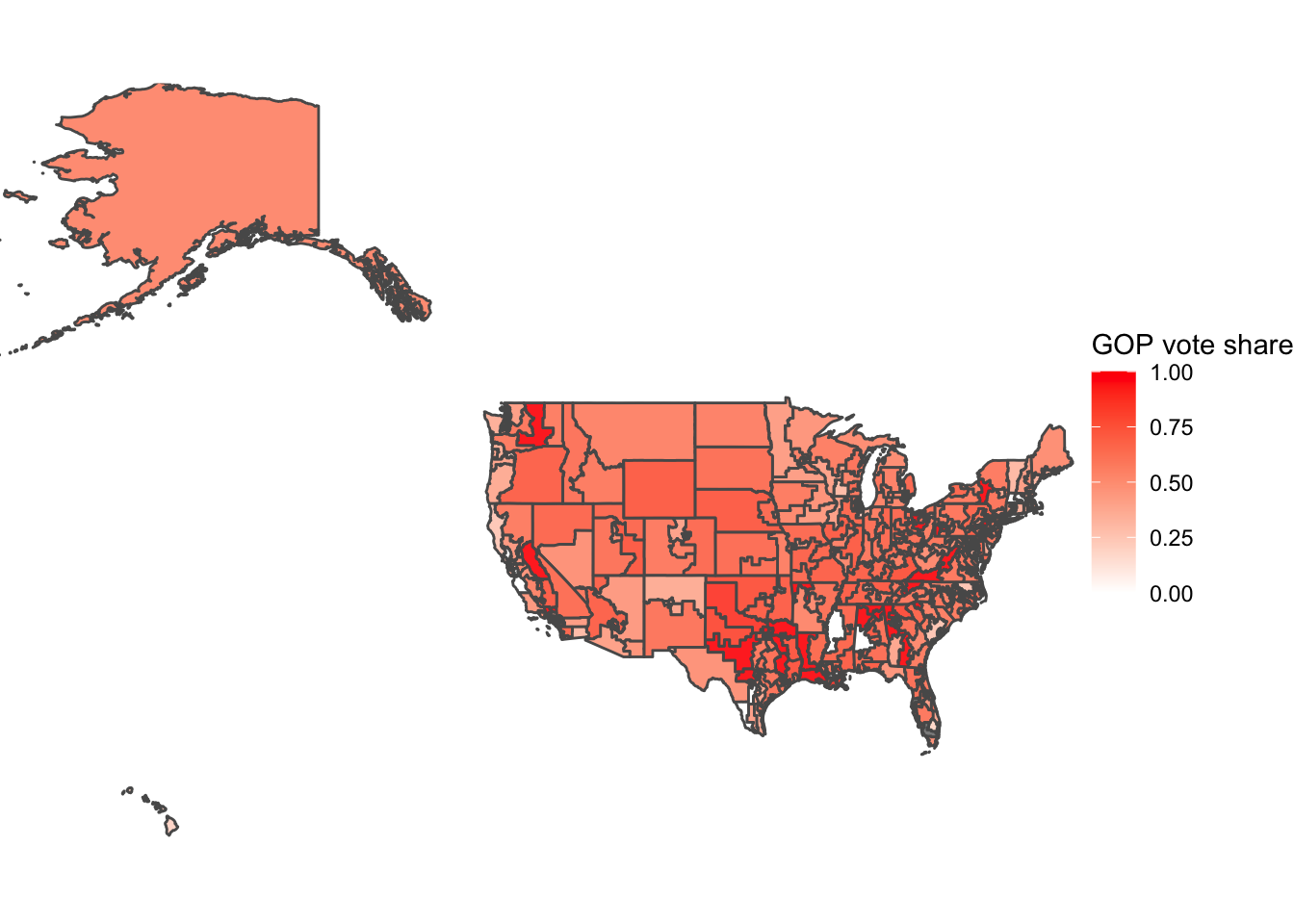
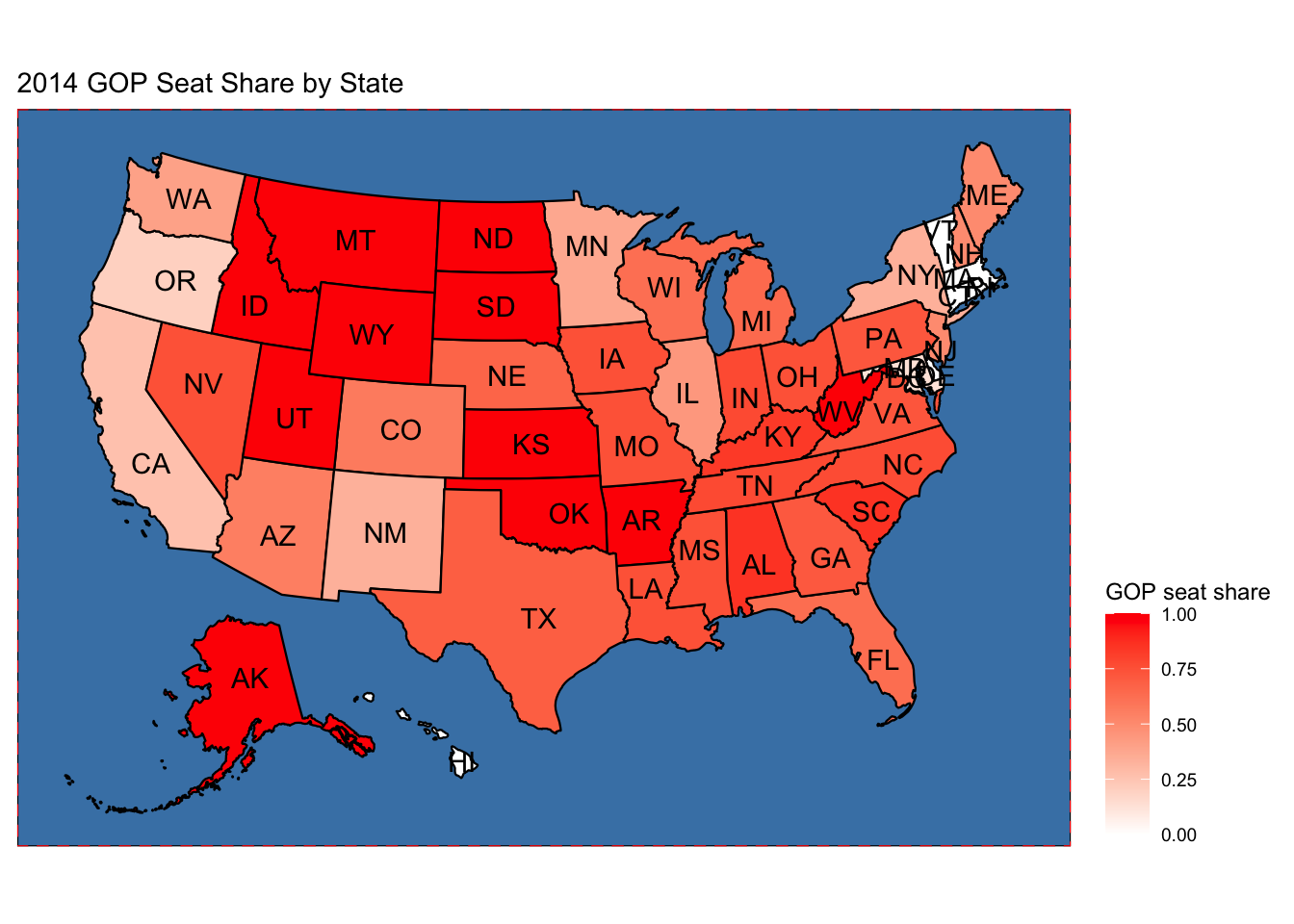
Having had some time to look at the results and compare with my own prediction and that of other forecasters, this week I will look at a particularly contentious district and investigate what might have led to prediction error. The Colorado 3rd district election was much closer than anticipated and had very interesting campaigns.
District Background
The Colorado third congressional district spans a massive 50,000 miles in western Colorado. The area is largely rural and has a median household income of $64,000. The college education rate is 35% and the median age is 42 years old. Amidst the wide stretches of beautiful landscape, CO-3 has two major cities: Grand Junction and Pueblo. Grand Junction is primarily inhabited by Republican voters, while Pueblo, which has a large Latino population and union labor, has more Democratic voters. The racial demographic of the district is three fourths white and one fourth hispanic/latino. During the 2020 census redistricting, the district shrunk overall losing most of its ground in the northern sections and gaining some ground along the southern border.
Representation for CO-3 has historically been split between both Republicans and Democrats with near perfect alternation until 2011. In recent history, a Democrat has not won since John Salazar was elected in 2004. The seat was then held by Scott Tipton for 10 years and then won by Lauren Boebert in 2020 after she defeated Scott in the Republican primary. Despite several Republican won elections, the vote share for Democrats has been increasing since 2014. The 2022 election was between the incumbent Lauren Boebert and the Democrat challenger Adam Frisch.
538 Forecast and Result
FiveThirtyEight predicted the CO-3 election outcome using a model created by Nate Silver. Silver’s model combines economic variables with polling data and adds in some expert predictions to create a prediction aggregate about the vote share in the district. A probability of winning is put together by taking a vote share distribution and running 40,000 simulations and counting the number that end up with Republican or Democratic majorities. For Colorado 3, they predicted a 97% chance that Boebert would win the election with vote share distribution centered around 57% in favor of the Republican candidate.
The prediction indicated a margin of 14 points between Boebert and Frisch. The actual result was a much closer race. The current vote tally reports Boebert winning by a margin of 0.2 percentage points.
The Campaigns
Lauren Boebert (R):
- Strongly conservative
- Won primary by large margin against Don Coram 63.9% to 36.1%
- Pro-life
- Top issues
- Inflation and Economy
- Veterans and Defense
- Getting Things Done
- Standing up for Local Communities
- Agriculture
Before running for office, Boebert’s experience included working as a natural gas product technician and owning Shooters Grill. When she announced she was running for re-election, she stated, “We don’t just need to take the House back in 2022, but we need to take the House back with fearless conservatives, strong Republicans, just like me.” Boebert has a traditional conservative stance supporting a small government, constitutional rights, and reducing regulations.
Adam Frisch (D):
- Democratic moderate. Demonstrates conservative values and feels very Republican
- Won primary by thin margin against Sol Sandoval 42.4% to 41.9%
- Pro-choice
- Top issues:
- Inflation
- Jobs
- Water
- Energy
- Veterans
Adam Frisch is a former Aspen City Councilman who describes himself as a “a pro-business, pro-energy, moderate, pragmatic Democrat.” His campaign emphasized that the economy and getting inflation under control were his top priorities. Frisch also campaigned on creating jobs and ensuring a Colorado water supply for future generations.
While Boebert seemed to be more focussed on national politics Frisch was actively appealing to the local politics. The largest discrepancy in their list of issues was the water supply issue which made the top five for Frisch but was the very last issue after 18 other issues on Boebert’s agenda. This might be because Boebert is an incumbent and already embroiled in national disputes and controversy. It is clear from Frisch’s campaign rhetoric that he was attacking Boebert on her “publicity stunts”, “raising money around the country”, and “extremist” beliefs. His attacks are an attempt to undercut her base by appealing to local issues like the water supply.
From a national benchmark, the election was really more like Republican versus Republican. Frisch took his stance as a fiscal conservative with his only Democratic qualities being his one or two under emphasized social views such as being pro choice. Boebert was strongly conservative across the board including social issues. Investigating Frisch’s campaign materials a little more, the strategy of “I’m a democrat but I’m the reasonable conservative” becomes more apparent. His website has more red than blue on it and his merchandise store sells a tee that says “I’m Adam Frisch, I’m not Nancy Pelosi.” Frisch’s conservative campaign is effective because most people in the district identify as Republicans. The Cook Political Report ranks CO-3 as “Solid Republican.” Frisch was trying to get a majority by being the more democratic candidate for the Latino vote and conservative enough to take Republicans away from aligning with a more hard line Candidate like Boebert.
Forecast Error
CO-3 was perhaps difficult to predict because of the unusual campaign that Frisch was running. Any model of historical data would expect the Democratic nominee to align themselves more with liberal ideologies. This is exemplified by how Frisch’s nomination was won only by a slight margin, indicating that it was difficult for a moderate of his type to win a Democratic primary. The decision made in that primary was probably the real unanticipated outcome for the forecasting models which are trained on traditional party candidates.
According to Lynn Vavreck’s campaign theory in “The Message Matters”, since the macroeconomic environment is bad and the incumbent party nationally is the Democratic party, Boebert should be running and insurgent campaign which highlights the economy while Frisch should be running a clarifying campaign which highlights a different issue to distract from the economy. This could not be father from the case in CO-3 however. I think the defining feature is that Frisch reframed Boebert and the Republicans as being the incumbent party and ran much more of an insurgent campaign himself. Boebert on the other hand ran a more clarifying campaign and focussed on social political issues rather than the national economy. The unusual nature of the campaigns made a difference in the ability of FiveThirtyEight to predict the election outcome.
References
Lynn Vavreck. The message matters: the economy and presidential campaigns. Princeton University Press, 2009. Lauren Boebert campaign website: https://boebert.house.gov Adam Frisch campaign website: https://www.adamforcolorado.com Ballotopedia election blog: https://ballotpedia.org/Colorado%27s_3rd_Congressional_District_election,_2022 FiveThirtyEight forecast: https://projects.fivethirtyeight.com/2022-election-forecast/house/

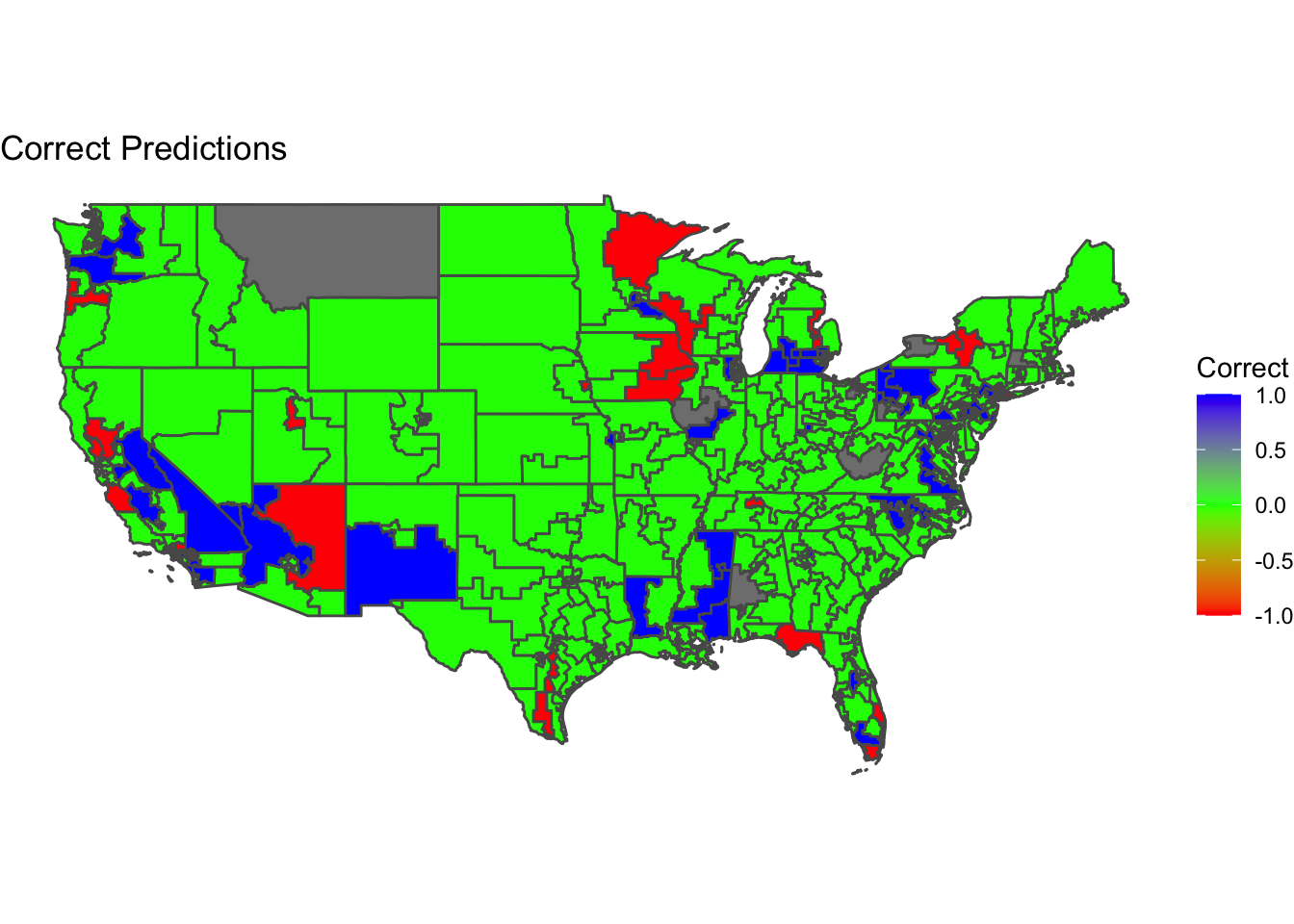 The districts colored in green were correctly characterized by the model while districts in red and blue were incorrect. Red means that the model predicted a Democratic candidate to win but a Republican won instead and blue means that the model predicted a Republican candidate to win but a Democrat won instead.
The districts colored in green were correctly characterized by the model while districts in red and blue were incorrect. Red means that the model predicted a Democratic candidate to win but a Republican won instead and blue means that the model predicted a Republican candidate to win but a Democrat won instead.
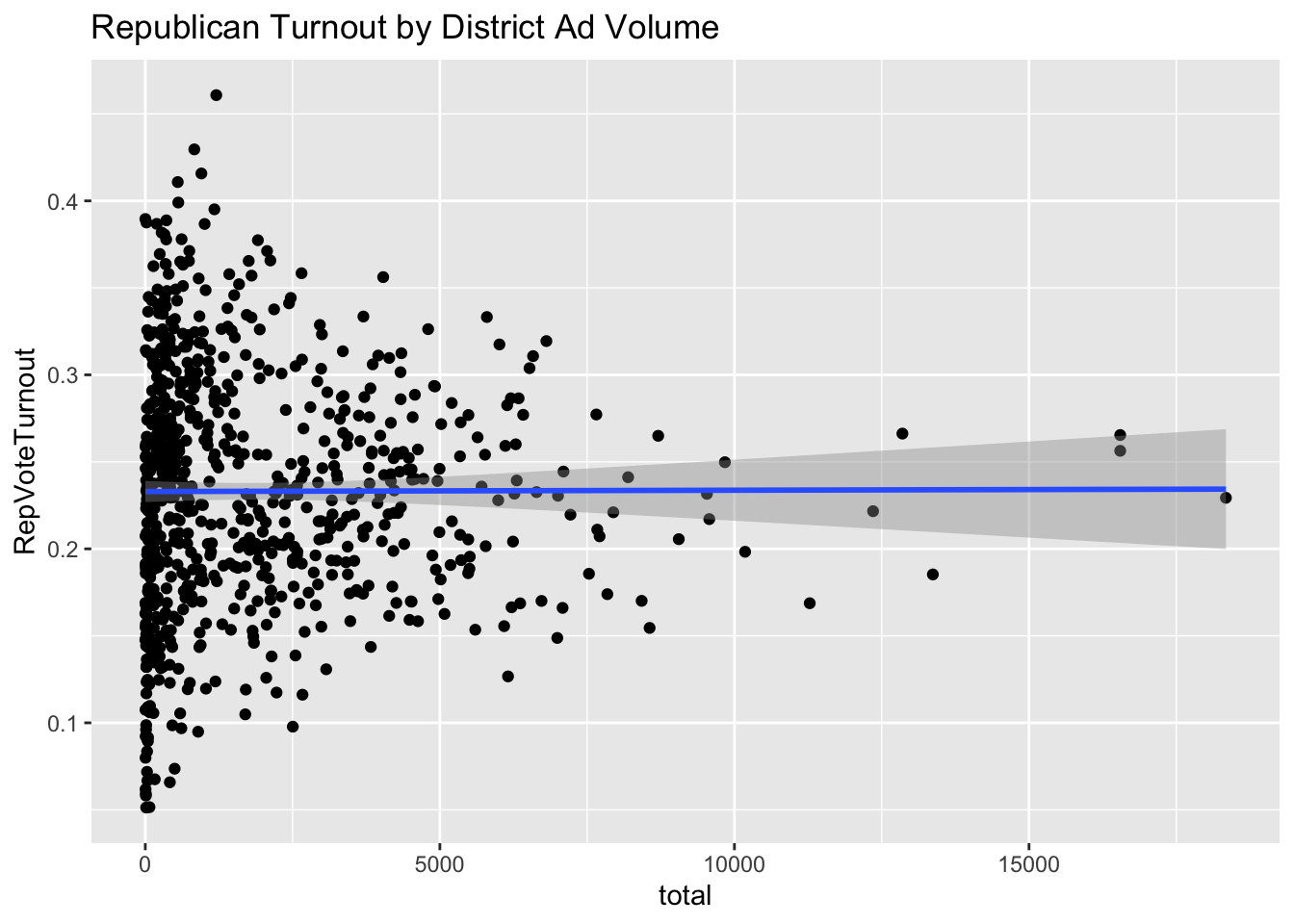
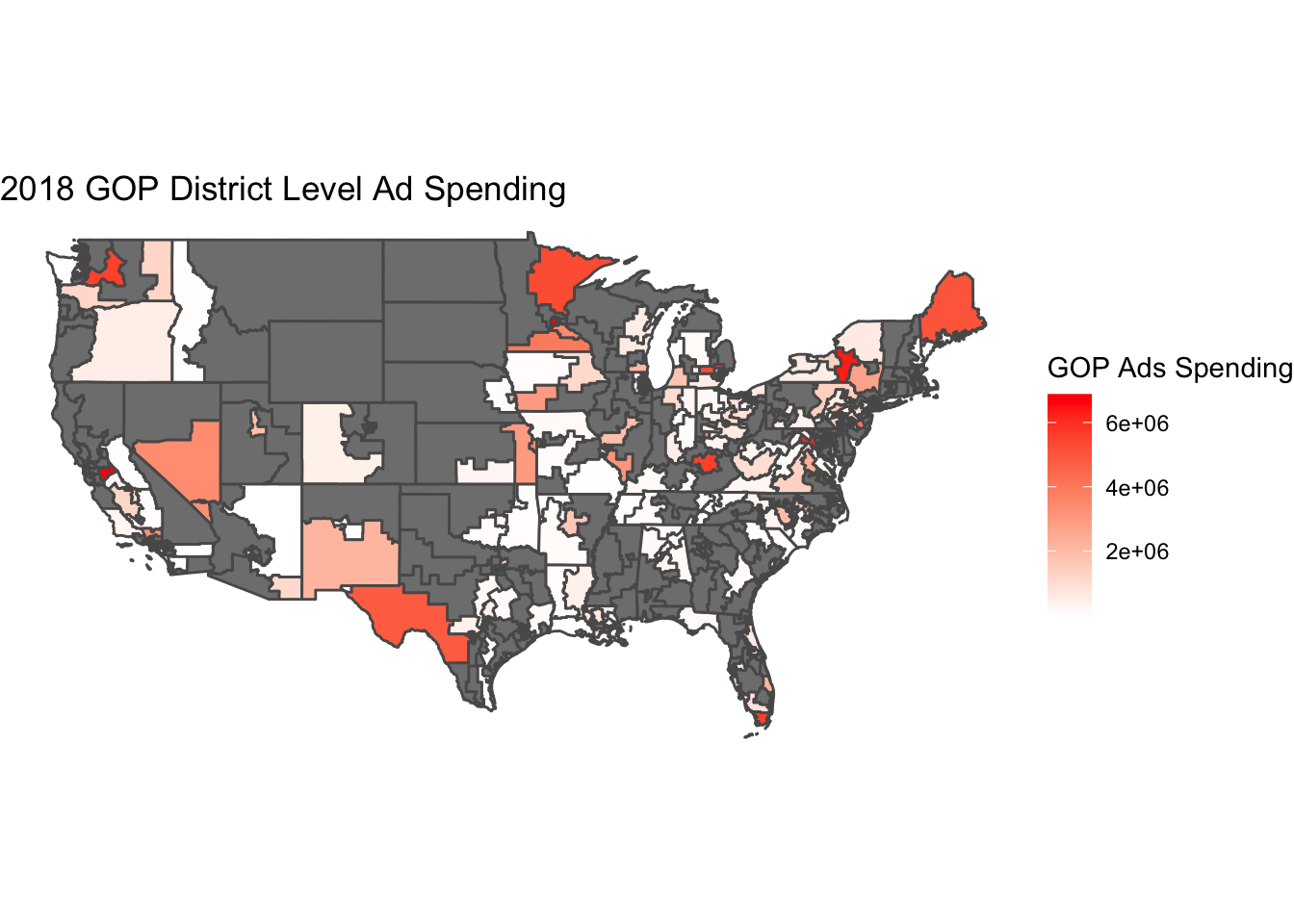
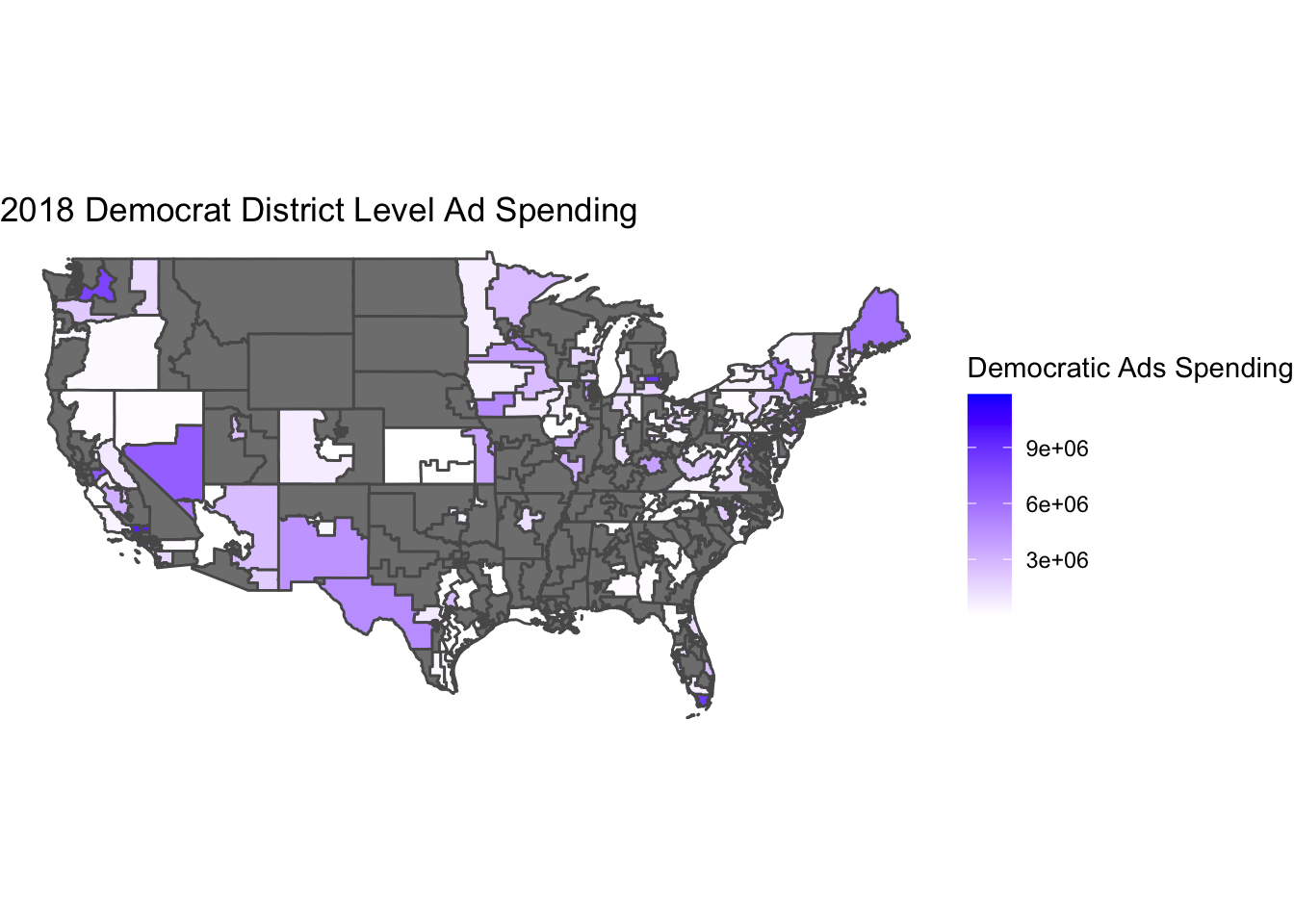
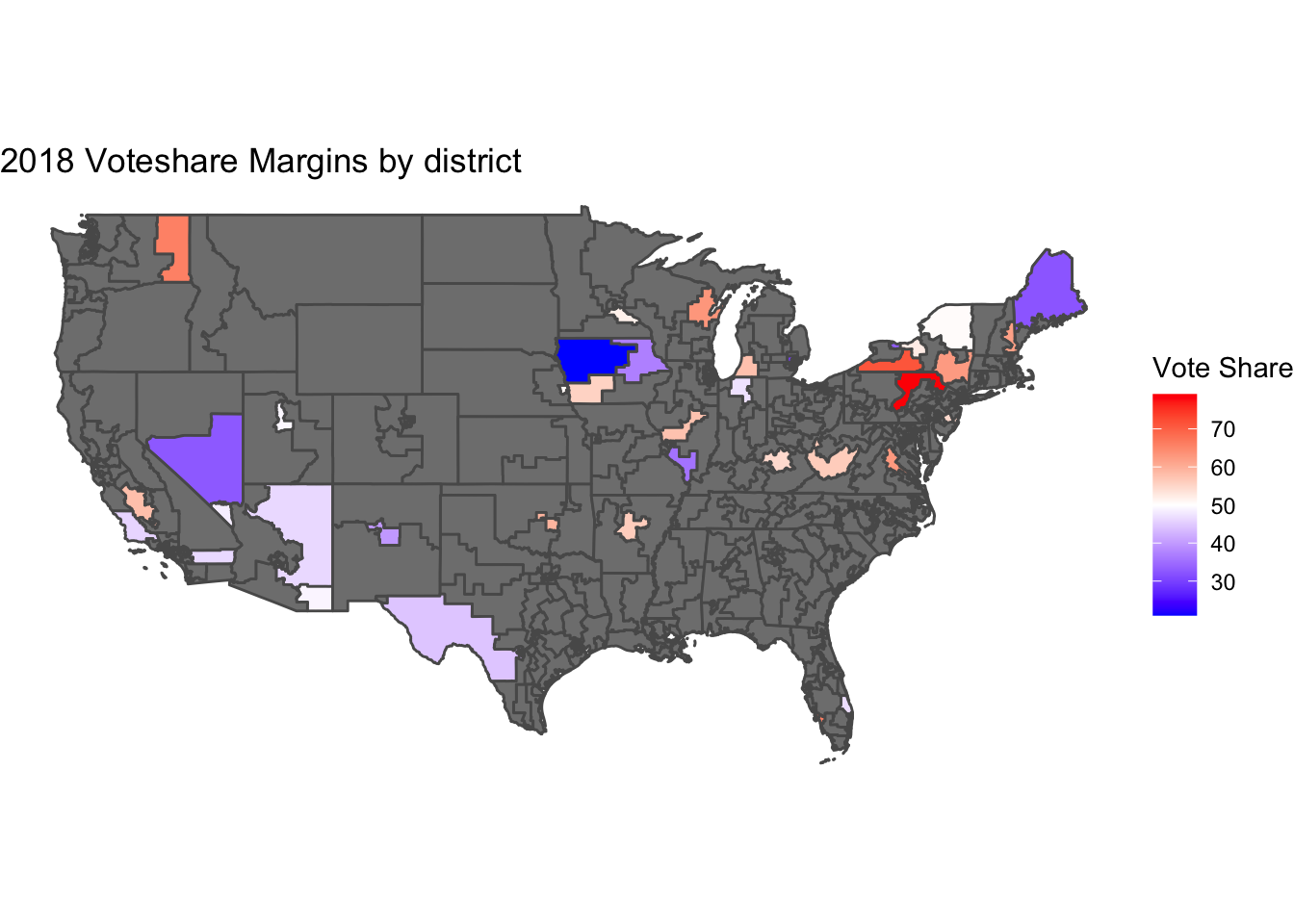
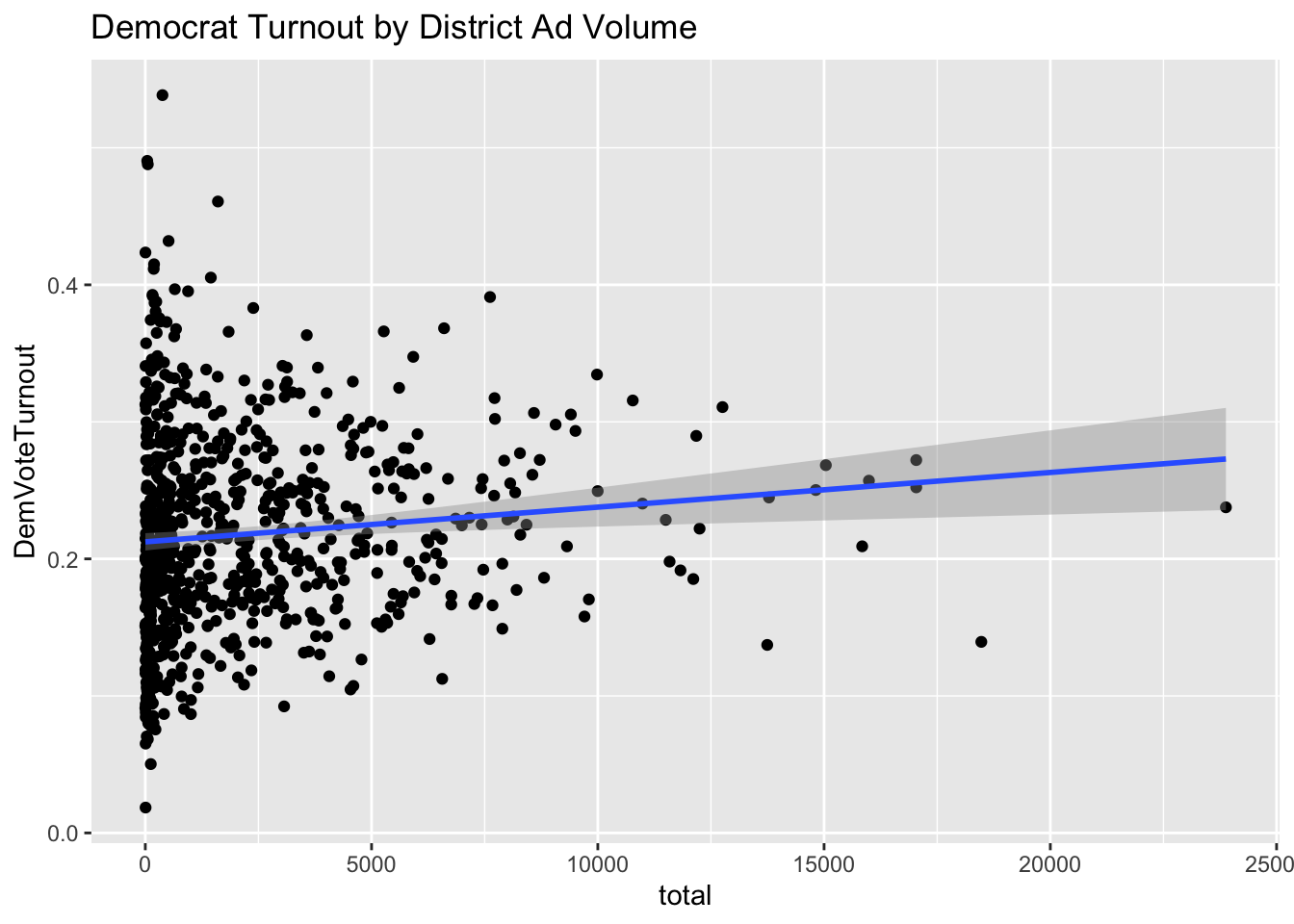 The charts above show a little correlation for Democrat ads and zero for Republican ads. This suggests that ads are largely ineffective at increasing voter turnout for a certain party. It is interesting to see that relative to each other, Democrat campaigns see more success in increasing voter turnout with advertisements.
The charts above show a little correlation for Democrat ads and zero for Republican ads. This suggests that ads are largely ineffective at increasing voter turnout for a certain party. It is interesting to see that relative to each other, Democrat campaigns see more success in increasing voter turnout with advertisements.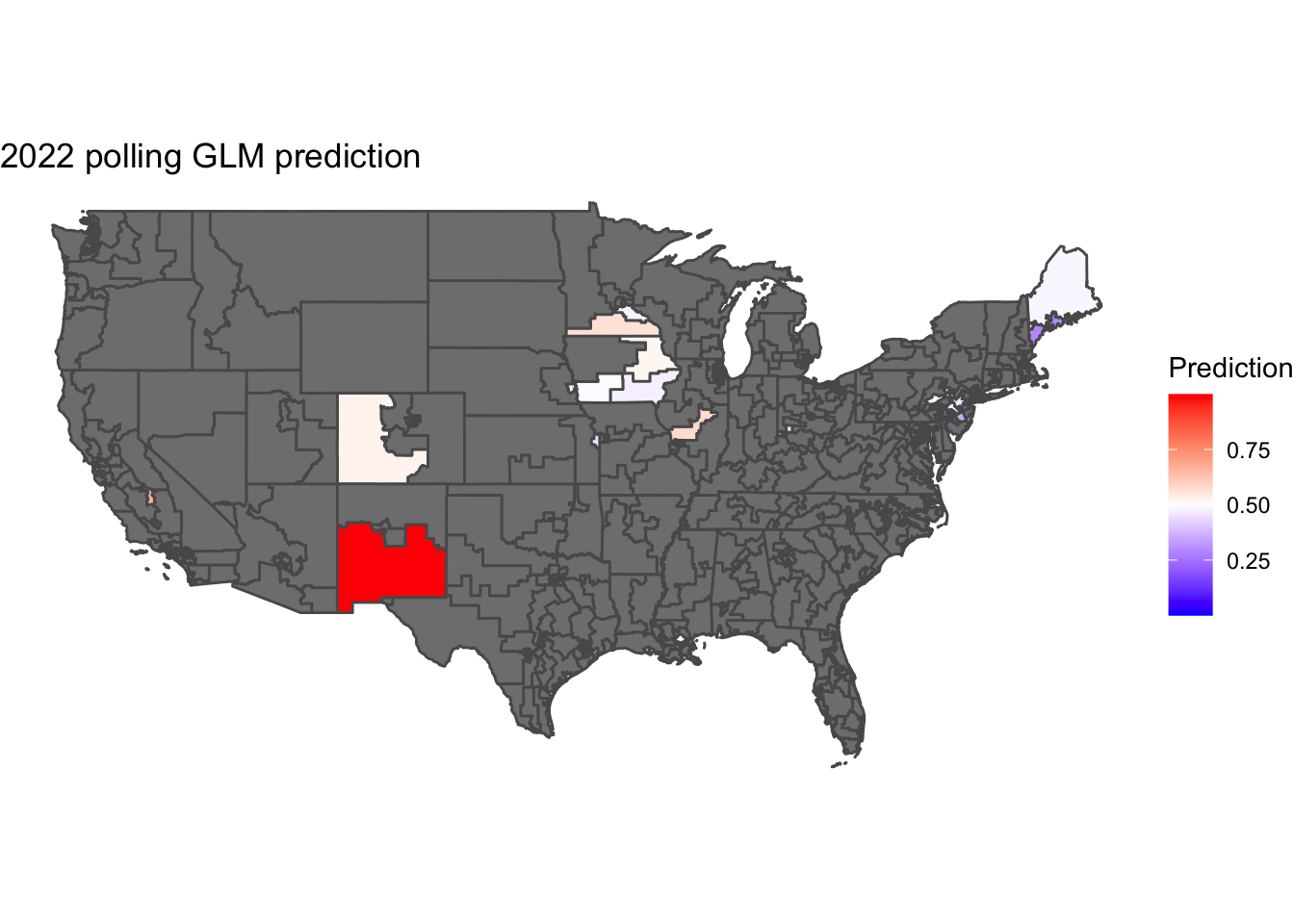 This approach is clearly not sufficient to make any sort of analysis. In order to make good predictions there needs to be more overlap in the available data about district populations and polling.
This approach is clearly not sufficient to make any sort of analysis. In order to make good predictions there needs to be more overlap in the available data about district populations and polling.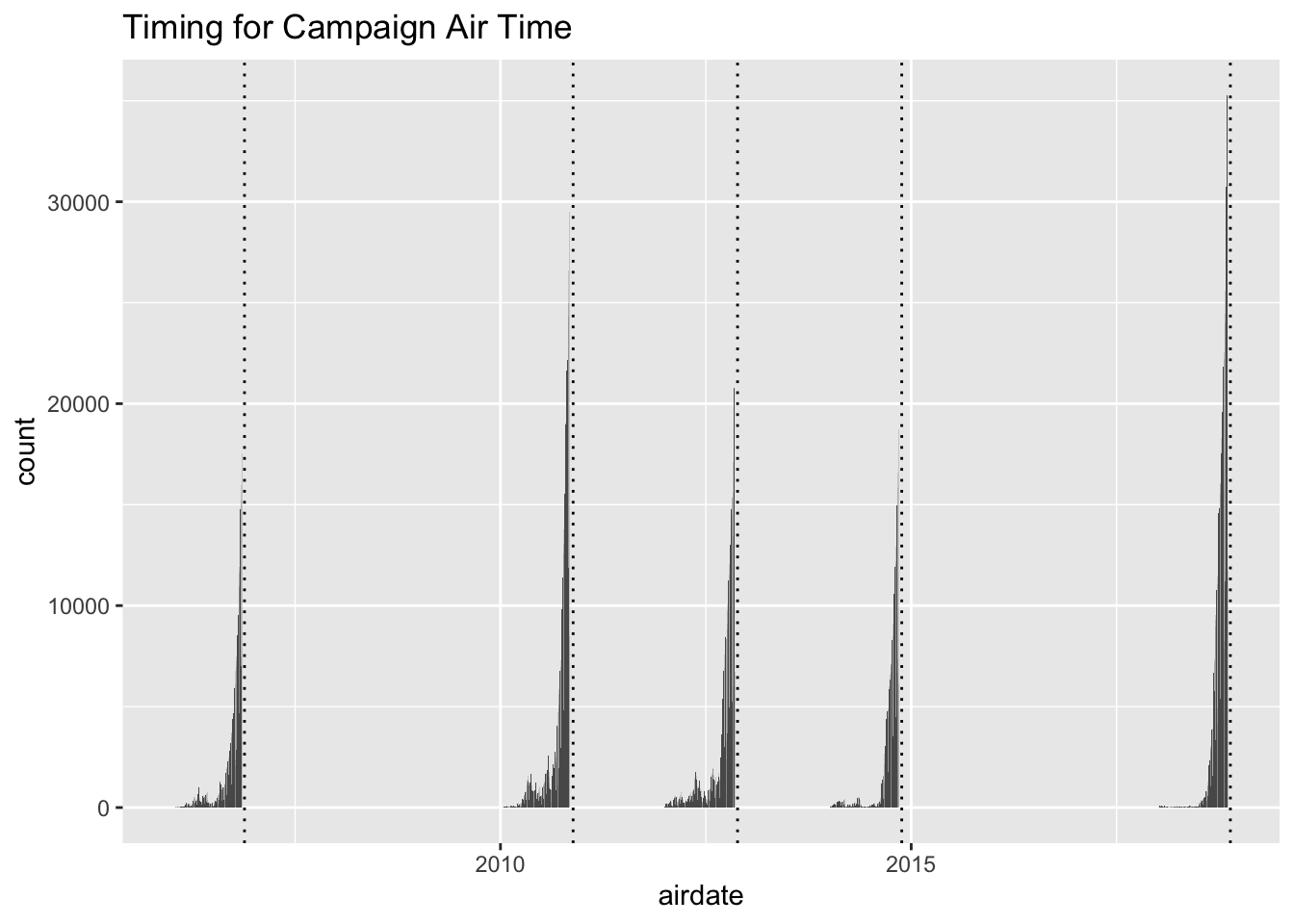
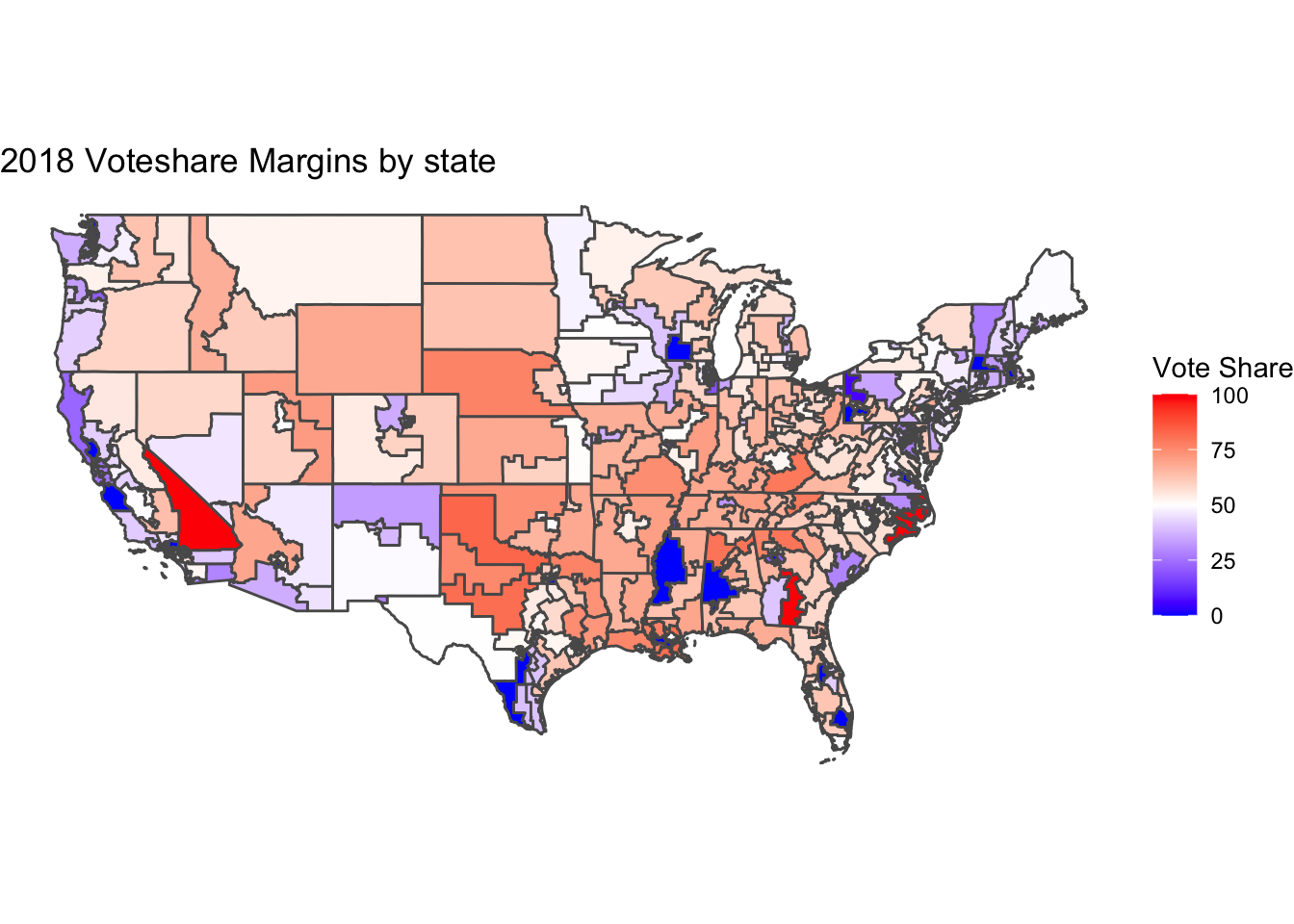
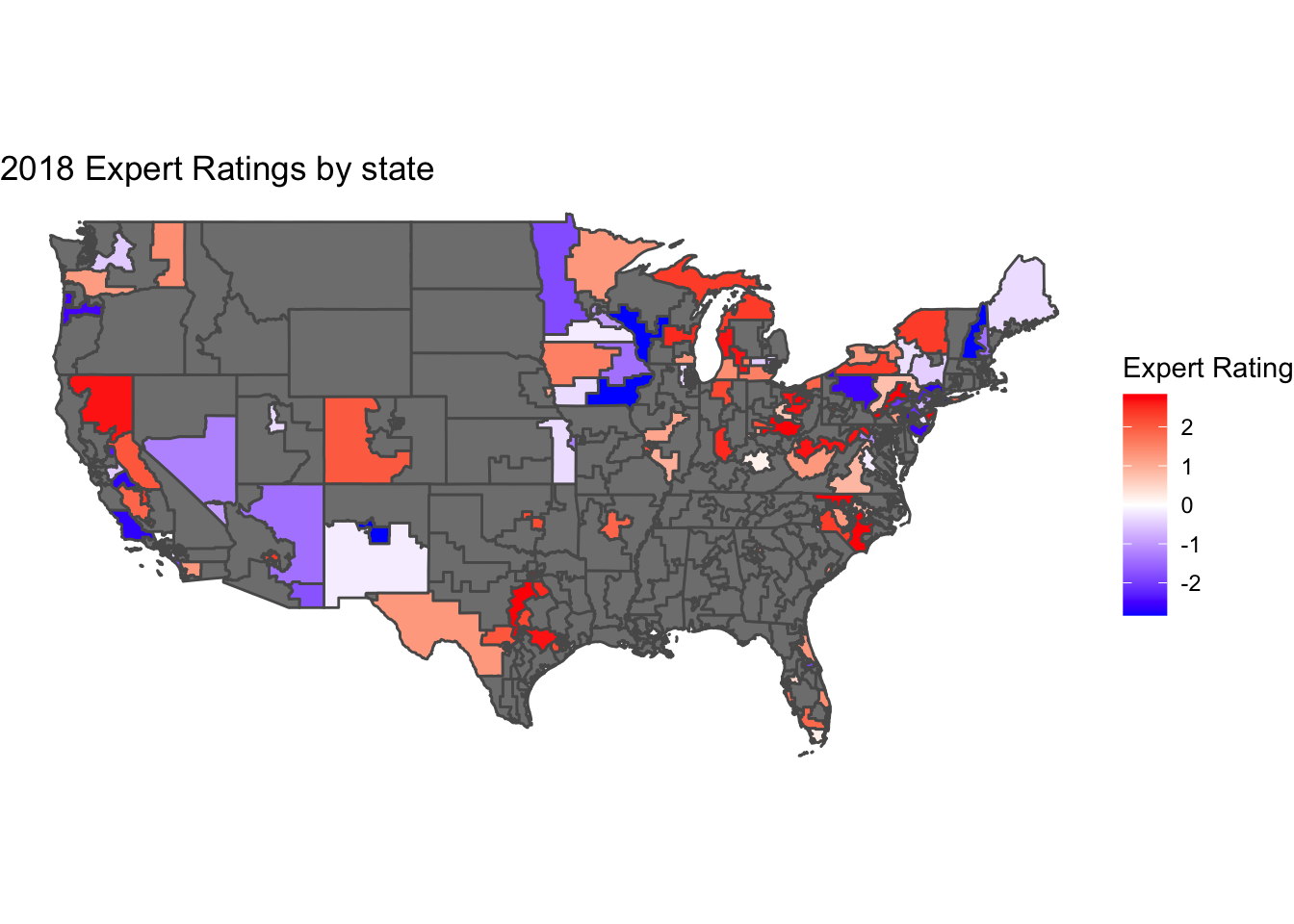

 We can notice a weak negative correlation between cpi increase and incumbent party seat share. Here the incumbent party is measured as the party with the plurality of the pre election incumbent representatives.
We can notice a weak negative correlation between cpi increase and incumbent party seat share. Here the incumbent party is measured as the party with the plurality of the pre election incumbent representatives.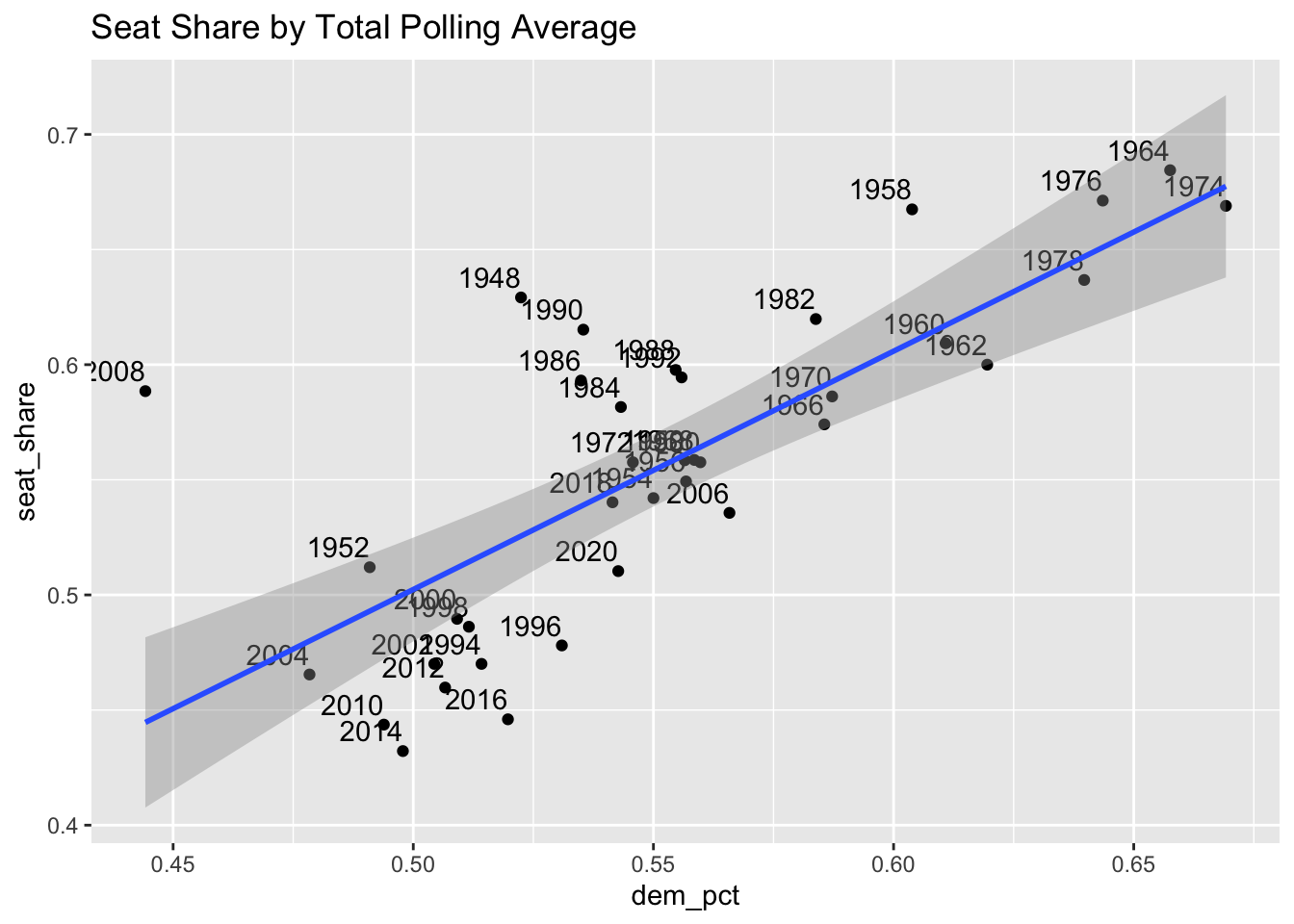
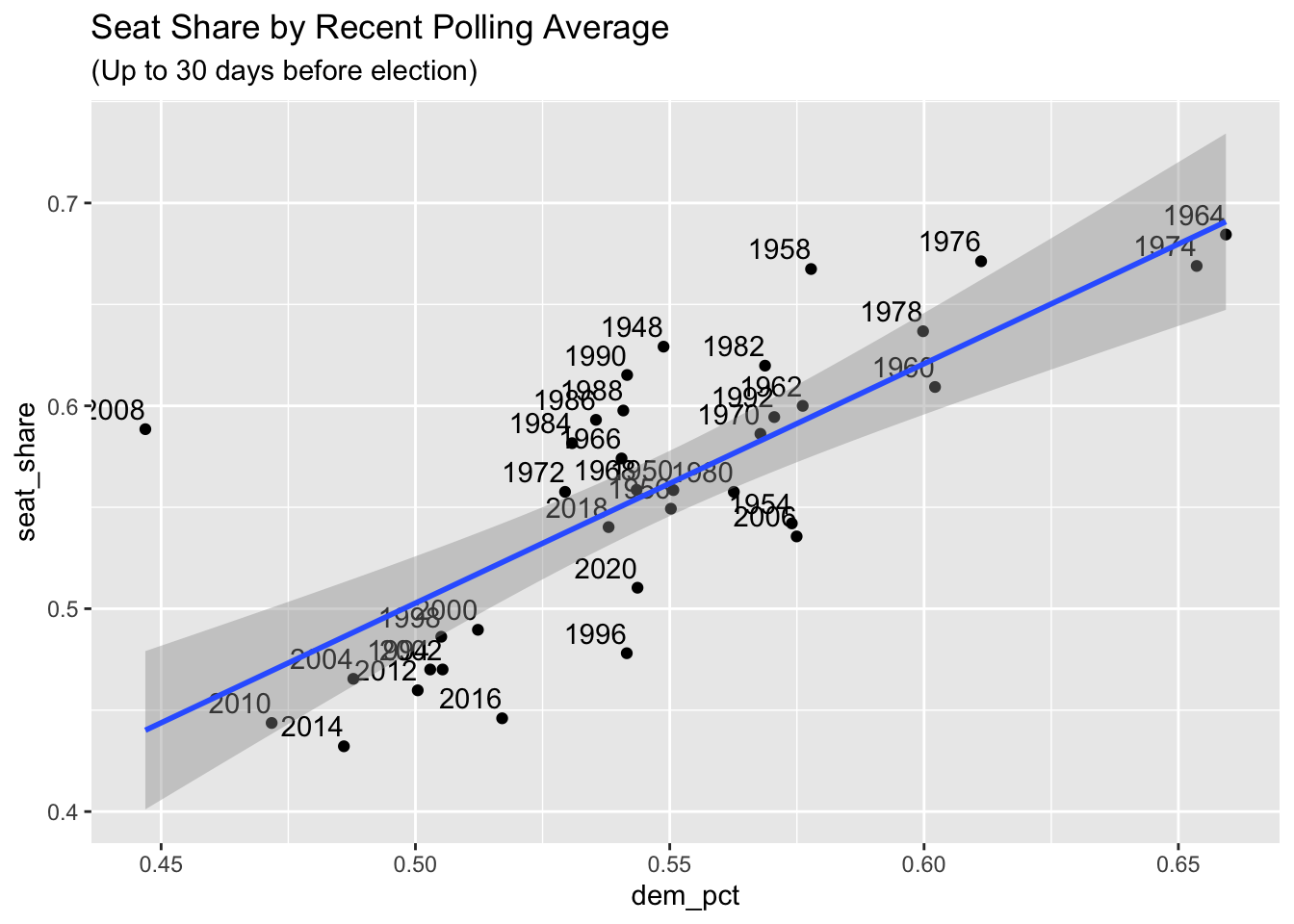
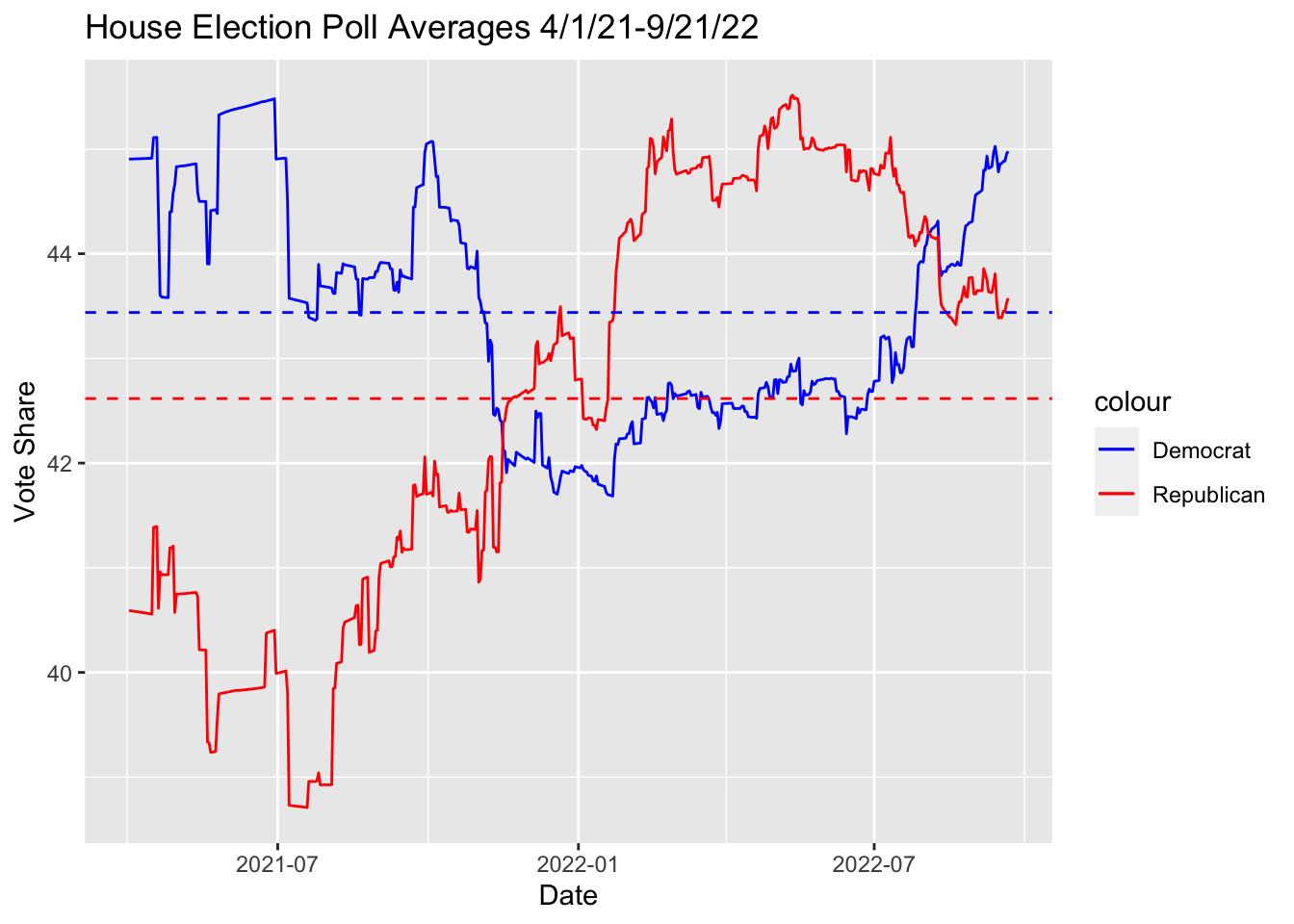
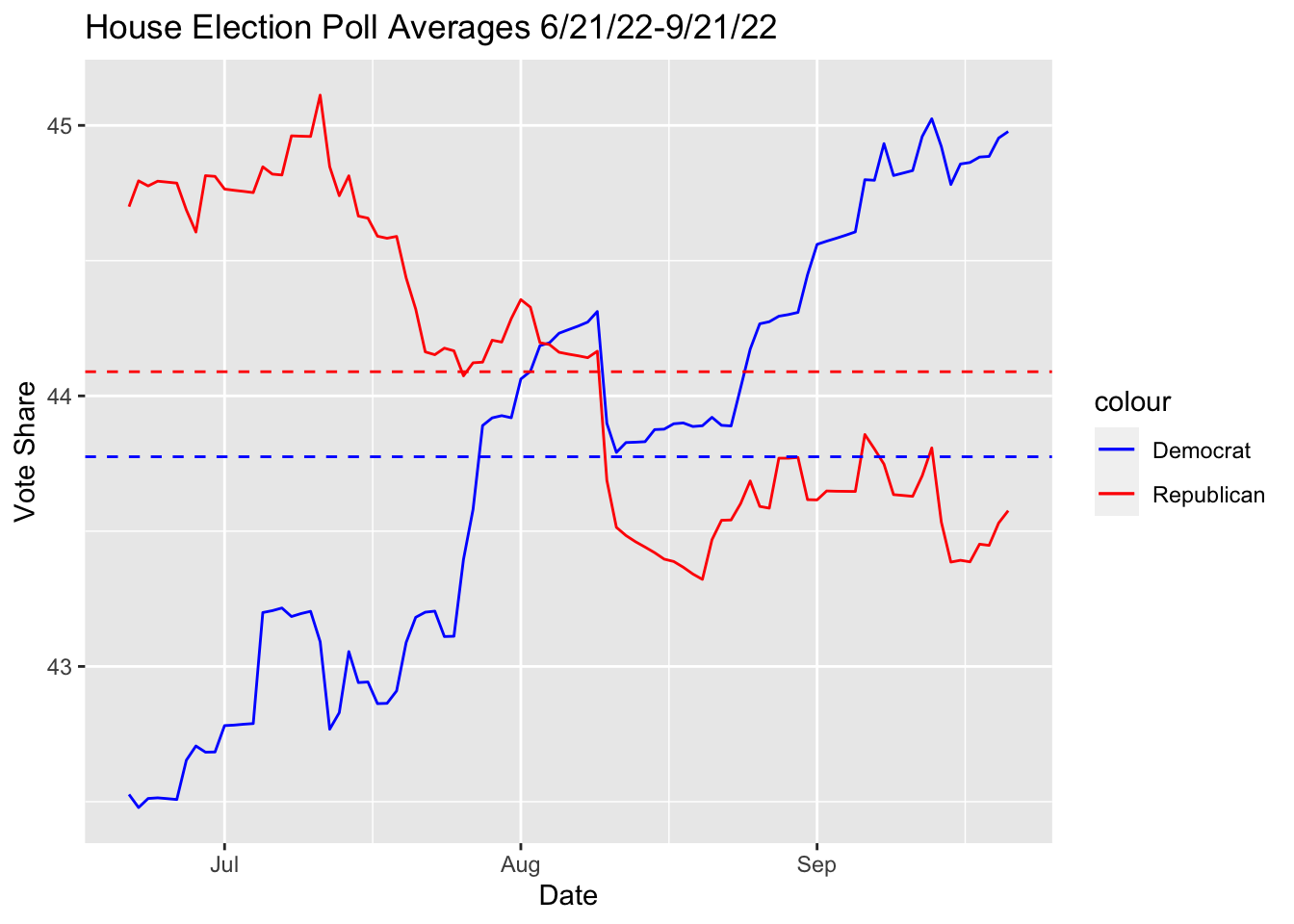
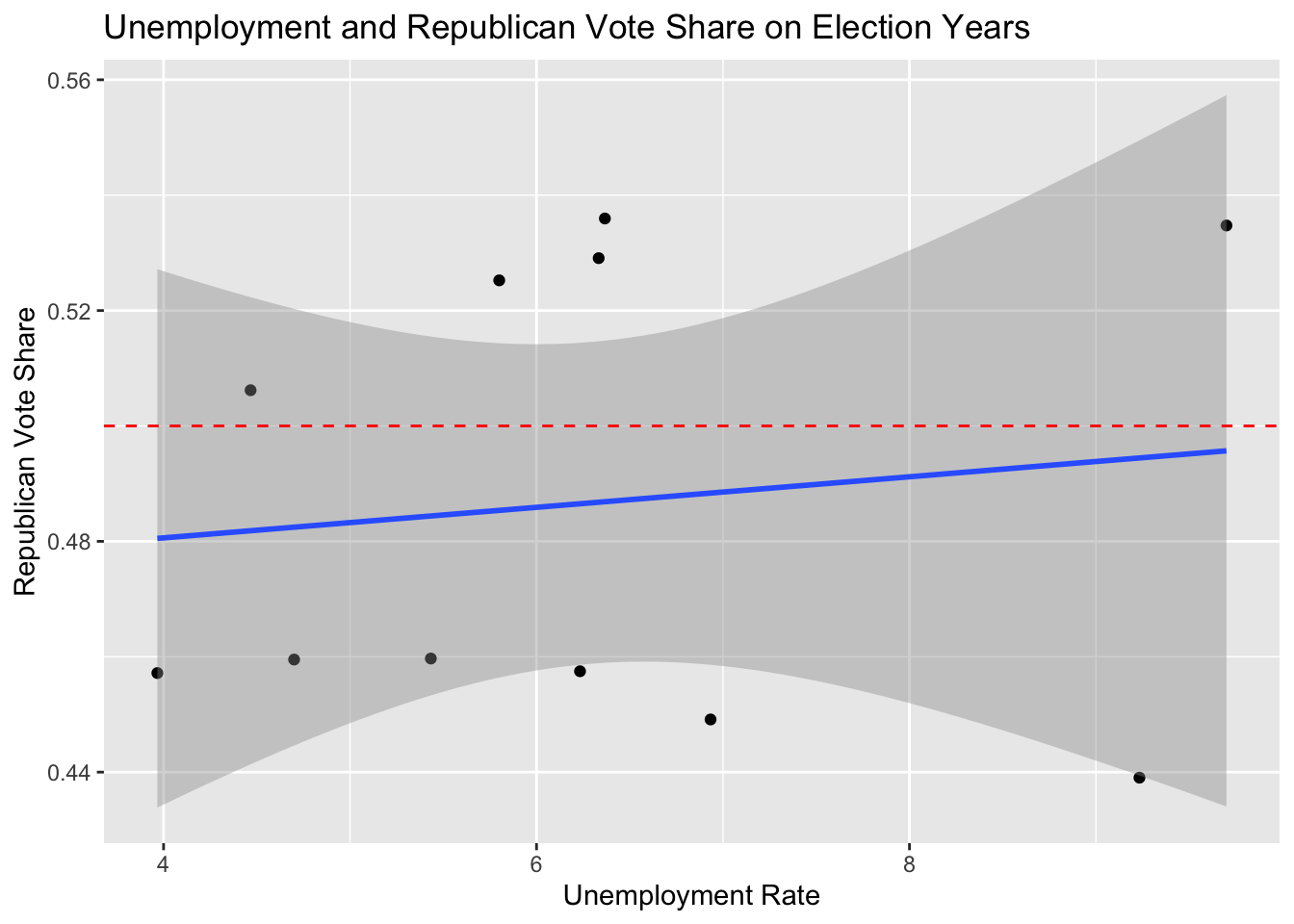
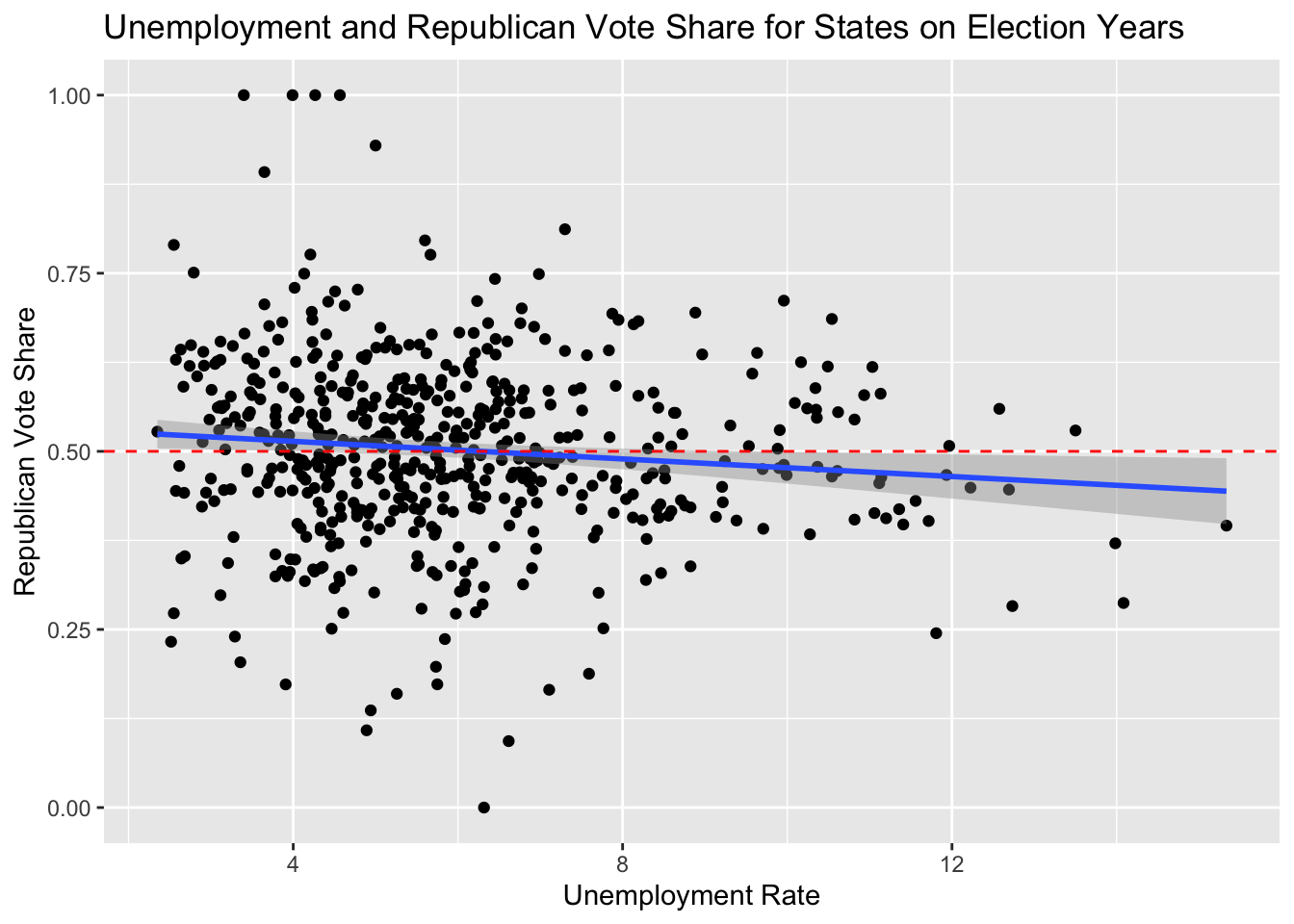 This chart gives a rough visualization of all data points from 1978 to 2018 for all midterm election years combined. Each dot represents data from one state on a certain election year. The midline of 50 percent vote share is marked in red. A result above the line means that the state’s districts were likely won by the Republican candidate and a result below the line similarly favors the Democratic candidate. The linear trend that the data follows is that on average, low unemployment on election years (2-6%) favors the Republican party and higher unemployment favors the platform of the Democratic Party (6+%).
This chart gives a rough visualization of all data points from 1978 to 2018 for all midterm election years combined. Each dot represents data from one state on a certain election year. The midline of 50 percent vote share is marked in red. A result above the line means that the state’s districts were likely won by the Republican candidate and a result below the line similarly favors the Democratic candidate. The linear trend that the data follows is that on average, low unemployment on election years (2-6%) favors the Republican party and higher unemployment favors the platform of the Democratic Party (6+%).